Design Principles
By definition, Design Patterns are reusable solutions to commonly occurring problems(in the context of software design).
Design patterns were started as best practices repeatedly applied to similar problems encountered in different contexts. They became popular after they were collected, in a formalized form, in the Gang Of Four book in 1994. Originally published with C++ and Smalltalk code samples, design patterns are very popular in Java, and C# can be applied in all object-oriented languages. In functional languages like Scala, certain patterns are not necessary anymore.
Design Principles
Software design principles represent a set of guidelines that helps us to avoid having a bad design. The design principles are associated with Robert Martin, who gathered them in "Agile Software Development: Principles, Patterns, and Practices". According to Robert Martin, there are 3 important characteristics of a bad design that should be avoided:
- Rigidity- It is hard to change because every change affects too many other parts of the system.
- Fragility- When you change, unexpected parts of the system break.
- Immobility- It is hard to reuse in another application because it cannot be disentangled from the current application.
Open Closed Principle
Software entities like classes, modules, and functions should be open for extension but closed for modifications.
OPC is a generic principle. You can consider it when writing your classes to make sure that you don't have to change the class but to extend it when you need to extend their behavior. The same principle can be applied to modules, packages, libraries. Suppose you have a library containing a set of classes. In that case, there are many reasons for which you'll prefer to extend it without changing the code that was already written (backward compatibility, regression testing). This is why we have to make sure our modules follow Open Closed Principle.
When referring to the classes, the Open Closed Principle can be ensured by using Abstract Classes and concrete classes to implement their behavior. This will enforce having Concrete Classes extending Abstract Classes instead of changing them. Some particular cases of this are Template Pattern and Strategy Pattern.
Motivation
A clever application design and the code writing part should take care of the frequent changes done during the development and maintenance phase of an application. Usually, many changes are involved when new functionality is added to an application. Those changes in the existing code should be minimized since it's assumed that it is already unit tested. Changes in already written code might affect the existing functionality in an unwanted manner.
The Open Closed Principle states that the code's design and writing should be done to add new functionality with minimum changes in the existing code. The design should be done to allow the adding of new functionality as new classes, keeping as much as possible existing code unchanged.
Intent
Software entities like classes, modules, and functions should be open for extension but closed for modifications.
Example
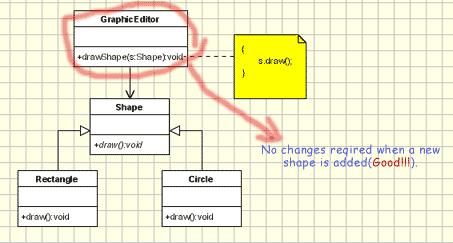
Below is an example that violates the Open Closed Principle. It implements a graphic editor who handles the drawing of different shapes. It does not follow the Open Closed Principle since the GraphicEditor class has to be modified for every new shape class that has to be added. There are several disadvantages:
- for each new shape added, the unit testing of the GraphicEditor should be redone.
- When a new type of shape is added, the time for adding it will be high since the developer who adds it should understand the logic of the GraphicEditor.
- adding a new shape might affect the existing functionality in an undesired way, even if the new shape works perfectly
To have a more dramatic effect, imagine that the Graphic Editor is a big class, with a lot of functionality inside, written and changed by many developers. At the same time, the shape might be a class implemented only by one developer. In this case, it would be a great improvement to add a new shape without changing the GraphicEditor class.

// Open-Close Principle - Bad example
class GraphicEditor {
public void drawShape(Shape s) {
if (s.m_type==1)
drawRectangle(s);
else if (s.m_type==2)
drawCircle(s);
}
public void drawCircle(Circle r) {....}
public void drawRectangle(Rectangle r) {....}
}
class Shape {
int m_type;
}
class Rectangle extends Shape {
Rectangle() {
super.m_type=1;
}
}
class Circle extends Shape {
Circle() {
super.m_type=2;
}
}Below is an example that supports the Open Closed Principle. In the new design, we use the abstract draw() method in GraphicEditor for drawing objects while moving the implementation in the concrete shape objects. Using the Open Closed Principle, the problems from the previous design are avoided because GraphicEditor is not changed when a new shape class is added:
- No unit testing is required.
- No need to understand the source code from GraphicEditor.
- Since the drawing code is moved to the concrete shape classes, it's a reduced risk to affect old functionality when new functionality is added.
// Open-Close Principle - Good example
class GraphicEditor {
public void drawShape(Shape s) {
s.draw();
}
}
class Shape {
abstract void draw();
}
class Rectangle extends Shape {
public void draw() {
// draw the rectangle
}
}Conclusion
Like every principle, OCP is only a principle. Making a flexible design involves additional time and effort spent for it, and it introduces a new level of abstraction, increasing the complexity of the code. So this principle should be applied in that area which is most likely to be changed.
Many design patterns help us to extend code without changing it. For instance, the Decorator pattern helps us follow the Open Closed Principle. Also, the Factory Method or the Observer pattern might be used to design an application that is easy to change with minimum changes in the existing code.
Dependency Inversion Principle
High-level modules should not depend on low-level modules. Both should depend on abstractions.
Abstractions should not depend on details. Details should depend on abstractions.
The dependency Inversion Principle states that we should decouple high-level modules from low-level modules, introducing an abstraction layer between high-level and low-level classes. Furthermore, it inverts dependency: instead of writing our abstractions based on details, we should write the details based on abstractions.
Dependency Inversion or Inversion of Control is a better-known term referring to how the dependencies are realized. Classically, when a software module(class, framework. etc.) needs some other module, it initializes and holds a direct reference to it. This will make the 2 modules tight coupled. To decouple them, the first module will provide a hook (a property, parameter, etc) and an external module controlling the dependencies will inject the reference to the second one.
By applying the Dependency Inversion, the modules can be easily changed by other modules just changing the dependency module. Factories and Abstract Factories can be used as dependency frameworks, but there are specialized frameworks known as Inversion of Control Container.
Motivation
When we design software applications, we can consider the low-level classes. These classes implement basic and primary operations(disk access, network protocols, …), and high-level classes encapsulate complex logic(business flows, …). The last ones rely on the low-level classes. A natural way of implementing such structures would be to write low-level classes and write the complex high-level classes once we have them. Since high-level classes are defined in terms of others, this seems the logical way to do it. But this is not a flexible design. What happens if we need to replace a low-level class?
Let's take the classic example of a copy module that reads characters from the keyboard and writes them to the printer device. The high-level class containing the logic is the Copy class. The low-level classes are KeyboardReader and PrinterWriter.
In a bad design, the high-level class uses directly and depends heavily on the low-level classes. In such a case, if we want to change the design to direct the output to a new FileWriter class, we have to make changes in the Copy class. (Let's assume that it is a very difficult class, with a lot of logic and hard to test).
We can introduce an abstraction layer between high-level and low-level classes to avoid such problems. Since the high-level modules contain complex logic, they should not depend on the low-level modules, so the new abstraction layer should not be created based on low-level modules. Low-level modules are to be created based on the abstraction layer.
According to this principle, the way of designing a class structure is to start from high-level modules to the low-level modules:
High-Level Classes → Abstraction Layer → Low-Level Classes
Intent
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
Example
Below is an example that violates the Dependency Inversion Principle. We have the manager class, a high-level class, and the low-level class, called Worker. We need to add a new module to our application to model the changes in the company structure determined by the employment of new specialized workers. We created a new class SuperWorker for this.
Let's assume the Manager class is quite complex, containing very complex logic. And now we have to change it to introduce the new SuperWorker. Let's see the disadvantages:
- we have to change the Manager class (remember it is a complex one, which will involve time and effort to make the changes).
- Some of the current functionality from the manager class might be affected.
- The unit testing should be redone.
All those problems could take a lot of time to be solved, and they might induce new errors in the old functionality. The situation would be different if the application were designed following the Dependency Inversion Principle. It means we design the manager class, an IWorker interface, and the Worker class implementing the IWorker Interface. When we need to add the SuperWorker class, we have to implement the IWorker Interface for it. No additional changes in the existing classes.
// Dependency Inversion Principle - Bad exampleclass Worker { public void work() { // ....working }}class Manager { Worker worker; public void setWorker(Worker w) {
worker = w;
} public void manage() {
worker.work();
}
}class SuperWorker {
public void work() {
//.... working much more
}
}
Below is the code which supports the Dependency Inversion Principle. A new abstraction layer is added through the IWorker Interface in this new design. Now the problems from the above code are solved(considering there is no change in the high-level logic):
- The manager class doesn't require changes when adding SuperWorkers.
- Minimized risk to affect old functionality present in Manager class since we don't change it.
- No need to redo the unit testing for the Manager class.
// Dependency Inversion Principle - Good example
interface IWorker {
public void work();
}class Worker implements IWorker{
public void work() {
// ....working
}
}class SuperWorker implements IWorker{
public void work() {
//.... working much more
}
}class Manager {
IWorker worker; public void setWorker(IWorker w) {
worker = w;
} public void manage() {
worker.work();
}
}
Conclusion
When this principle is applied, the high-level classes are not working directly with low-level classes. They are using interfaces as an abstract layer. In this case, instantiation of new low-level objects inside the high-level classes(if necessary) can not be done using the new operator. Instead, some Creational design patterns can be used, such as Factory Method, Abstract Factory, Prototype.
The Template Design Pattern is an example where the DIP principle is applied.
Of course, using this principle implies an increased effort, which will result in more classes and interfaces to maintain, in a few words, in more complex code, but more flexible. This principle should not be applied blindly for every class or every module. If we have a class functionality that is more likely to remain unchanged in the future, there is no need to apply this principle.
Interface Segregation Principle
Clients should not be forced to depend upon interfaces that they don’t use.
This principle teaches us to take care of how we write our interfaces. When we write our interfaces, we should add only methods that should be there. If we add methods that should not be there, the Interface classes will also have to implement those methods. For example, if we create an interface called Worker and add a method lunch break, all the workers will have to implement it. What if the Worker is a robot?
In conclusion, Interfaces containing methods that are not specific to it are called polluted or fat interfaces. We should avoid them.
Motivation
When we design an application, we should take care of how we abstract a module containing several submodules. Considering the module implemented by a class, we can abstract the system in an interface. But suppose we want to extend our application by adding another module that contains only some of the submodules of the original system. In that case, we are forced to implement the full Interface and write some dummy methods. Such an interface is named fat interface or polluted Interface. Having interface pollution is not a good solution and might induce inappropriate behavior in the system.
The Interface Segregation Principle states that clients should not be forced to implement interfaces they don't use. Instead of one fat interface, many small interfaces are preferred based on groups of methods, each one serving one submodule.
Intent
Clients should not be forced to depend upon interfaces that they don't use.
Example
Below is an example that violates the Interface Segregation Principle. We have a Manager class which represents the person who manages the workers. And we have 2 types of workers, some average and some very efficient workers. Both types of workers works, and they need a daily launch break to eat. But now some robots came in the company they work in, but they don't eat so they don't need a launch break. The new Robot class needs to implement the IWorker Interface on the side because robots work. On the other side, they don't have to implement it because they don't eat.
In this case, the IWorker is considered a polluted interface.
If we keep the present design, the new Robot class will implement the eat method. We can write a dummy class that does nothing(let's say a launch break of 1 second daily) and can have undesired effects in the application(For example, the reports seen by managers will report more lunches taken than the number of people).
According to the Interface Segregation Principle, a flexible design will not have polluted interfaces. In our case, the IWorker interface should be split into 2 different interfaces.
// interface segregation principle - bad example
interface IWorker {
public void work();
public void eat();
}class Worker implements IWorker{
public void work() {
// ....working
}
public void eat() {
// ...... eating in launch break
}
}class SuperWorker implements IWorker{
public void work() {
//.... working much more
} public void eat() {
//.... eating in launch break
}
}class Manager {
IWorker worker; public void setWorker(IWorker w) {
worker=w;
} public void manage() {
worker.work();
}
}
Following it's the code supporting the Interface Segregation Principle. By splitting the IWorker Interface into 2 different interfaces, the new Robot class is no longer forced to implement the eat method. Also, if we need another functionality for the robot-like recharging, we create another interface IRechargeble with a method recharge.
// interface segregation principle - good example
interface IWorker extends Feedable, Workable {
}interface IWorkable {
public void work();
}interface IFeedable{
public void eat();
}class Worker implements IWorkable, IFeedable{
public void work() {
// ....working
} public void eat() {
//.... eating in launch break
}
}class Robot implements IWorkable{
public void work() {
// ....working
}
}class SuperWorker implements IWorkable, IFeedable{
public void work() {
//.... working much more
} public void eat() {
//.... eating in launch break
}
}class Manager {
Workable worker; public void setWorker(Workable w) {
worker=w;
} public void manage() {
worker.work();
}
}
Conclusion
If the design is already done, fat interfaces can be segregated using the Adapter pattern.
Like every principle Interface, the Segregation Principle is one principle that requires additional time and effort spent to apply it during the design time and increase the complexity of code. But it produces a flexible design. Suppose we apply it more than is necessary. In that case, it will result in a code containing a lot of interfaces with single methods, so applying should be done based on experience and common sense in identifying the areas where extension of code is more likely to happen in the future.
Single Responsibility Principle
A class should have only one reason to change.
In this context, responsibility is considered to be one reason to change. This principle states that if we have 2 reasons to change for a class, we must split the functionality into two classes. Each class will handle only one responsibility, and in the future, if we need to make one change, we will make it in the class that handles it. When we need to make a change in a class having more responsibilities, the change might affect the other functionality of the classes.
Tom DeMarco introduced the Single Responsibility Principle in his book Structured Analysis and Systems Specification, 1979. Robert Martin reinterpreted the concept and defined responsibility as a reason to change.
Motivation
In this context, responsibility is considered to be one reason to change. This principle states that if we have 2 reasons to change for a class, we must split the functionality into two classes. Each class will handle only one responsibility, and if we need to make one change in the future, we will make it in the class that handles it. When we need to make a change in a class having more responsibilities, the change might affect the other functions related to the other responsibility of the class.
The Single Responsibility Principle is simple and intuitive, but it is sometimes hard to get it right in practice.
Intent
A class should have only one reason to change.
Example
Let's assume we need an object to keep an email message. We are going to use the IEmail Interface from the below sample. At first sight, everything looks just fine. At a closer look, we can see that our IEmail Interface and Email class have 2 responsibilities (reasons to change). One would be the use of the class in some email protocols such as pop3 or IMAP. If other protocols must be supported, the objects should be serialized, and code should be added to support new protocols. Another one would be for the Content field. Even if the content is a string, maybe we want to support HTML or other formats in the future.
If we keep only one class, each responsibility change might affect the other one:
- Adding a new protocol will create the need to add code for parsing and serializing the content for each type of field.
- Adding a new content type (like HTML) adds code for each protocol implemented.
// single responsibility principle - bad exampleinterface IEmail {
public void setSender(String sender);
public void setReceiver(String receiver);
public void setContent(String content);
}class Email implements IEmail {
public void setSender(String sender) {// set sender; }
public void setReceiver(String receiver) {// set receiver; }
public void setContent(String content) {// set content; }
}
We can create a new interface and class called IContent and Content to split the responsibilities. Having only one responsible for each class gives us a more flexible design:
- adding a new protocol causes changes only in the Email class.
- Adding a new type of content supported causes changes only in the Content class.
// single responsibility principle - good example
interface IEmail {
public void setSender(String sender);
public void setReceiver(String receiver);
public void setContent(IContent content);
}interface Content {
public String getAsString(); // used for serialization
}class Email implements IEmail {
public void setSender(String sender) {// set sender; }
public void setReceiver(String receiver) {// set receiver; }
public void setContent(IContent content) {// set content; }
}
Conclusion
The Single Responsibility Principle represents a good way of identifying classes during the design phase of an application. It reminds you to think of all the ways a class can evolve. A good separation of responsibilities is done only when the application's full picture is well understood.
Liskov's Substitution Principle
Derived types must be completely substitutable for their base types.
This principle is just an extension of the Open Closed Principle in terms of behavior, meaning that we must make sure that new derived classes are extending the base classes without changing their behavior. The new derived classes should be able to replace the base classes without any change in the code.
Barbara Liskov introduced Liskov's Substitution Principle in a 1987 Conference on Object-Oriented Programming Systems Languages and Applications in Data abstraction and hierarchy.
Motivation
We always design a program module and create some class hierarchies. Then we extend some classes creating some derived classes.
We must make sure that the new derived classes extend without replacing the functionality of old classes. Otherwise, the new classes can produce undesired effects when they are used in existing program modules.
Liskov's Substitution Principle states that if a program module uses a Base class, then the reference to the Base class can be replaced with a Derived class without affecting the functionality of the program module.
Intent
Derived types must be completely substitutable for their base types.
Example
Below is the classic example for which Liskov's Substitution Principle is violated. In the example, 2 classes are used: Rectangle and Square. Let's assume that the Rectangle object is used somewhere in the application. We extend the application and add the Square class. Based on some conditions, the square class is returned by a factory pattern, and we don't know exactly what type of object will be returned. But we know it's a Rectangle. We get the rectangle object, set the width to 5 and height to 10, and get the area. For a rectangle with a width of 5 and a height of 10, the area should be 50. Instead, the result will be 100
// Violation of Likov's Substitution Principle
class Rectangle
{
protected int m_width;
protected int m_height; public void setWidth(int width){
m_width = width;
} public void setHeight(int height){
m_height = height;
}
public int getWidth(){
return m_width;
} public int getHeight(){
return m_height;
} public int getArea(){
return m_width * m_height;
}
}class Square extends Rectangle
{
public void setWidth(int width){
m_width = width;
m_height = width;
} public void setHeight(int height){
m_width = height;
m_height = height;
}}class LspTest
{
private static Rectangle getNewRectangle()
{
// it can be an object returned by some factory ...
return new Square();
} public static void main (String args[])
{
Rectangle r = LspTest.getNewRectangle();
r.setWidth(5);
r.setHeight(10);
// user knows that r it's a rectangle.
// It assumes that he's able to set the width and height as for the base class System.out.println(r.getArea());
// now he's surprised to see that the area is 100 instead of 50.
}
}
Conclusion
This principle is just an extension of the Open Closed Principle, and it means that we must make sure that new derived classes are extending the base classes without changing their behavior.
Author: https://www.linkedin.com/in/shivam-ross/ | https://twitter.com/BeastofBayArea | https://www.instagram.com/sup.its.shiv/
